 2.
はじめてのGemini API
2.
はじめてのGemini API
Gemini API をはじめる
Google AI Studio
Gemini API の開発は Google AI Studio でAPIキーの発行が必要です。
開発環境
Gemini APIのドキュメント
Gemini APIの内容を理解するには、公式:Gemini API のドキュメントで確認できます。
- このドキュメントは、バージョンアップとともに修正されます。
必要なツールとライブラリ
| 項目 | パッケージマネージャー | パッケージ・ライブラリ |
|---|---|---|
| Python | pip, conda | GoogleGenerativeAI |
| Node.js | npm | GoogleGenerativeAI |
| iOS, Android | 各種パッケージマネージャー | GenerativeModel |
| PHP | composer | REST、Guzzle |
APIキーの作成
Gemini APIを利用するには、Google AI Studioのアカウント作成とAPIキー取得が必要です。 「Google AI Studio」にアクセスします。

- Googleアカウント(Gmail)でログインします。
ホーム画面
「Google AI Studio」のホーム画面です。
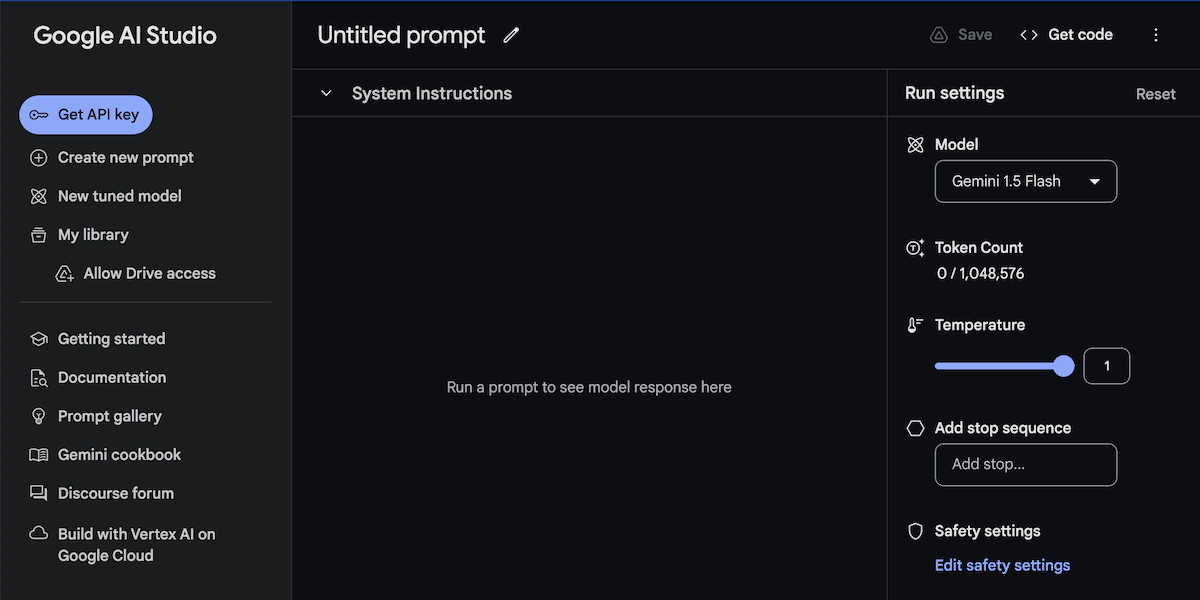
Get API Key にアクセス
【Get API Key】にアクセスします。
APIキー作成(はじめて作成する場合)
以下のダイアログで【新しいプロジェクトでAPIキーを作成】をクリックします。
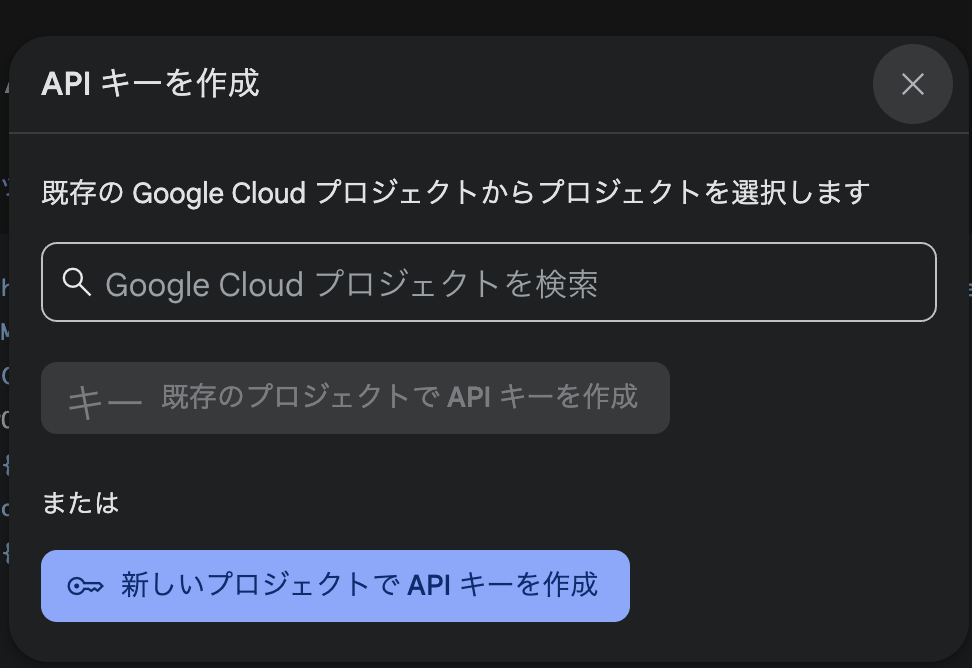
APIキーの発行
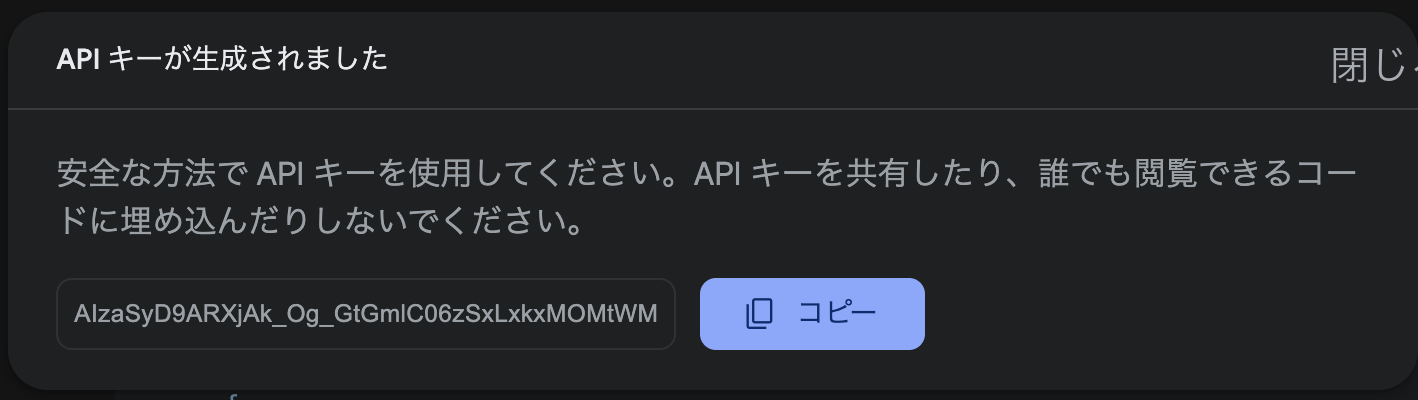
APIキーが発行されたら、コピーして忘れないようにメモしておきます。また、このキーは外部に流出しないように注意してください。
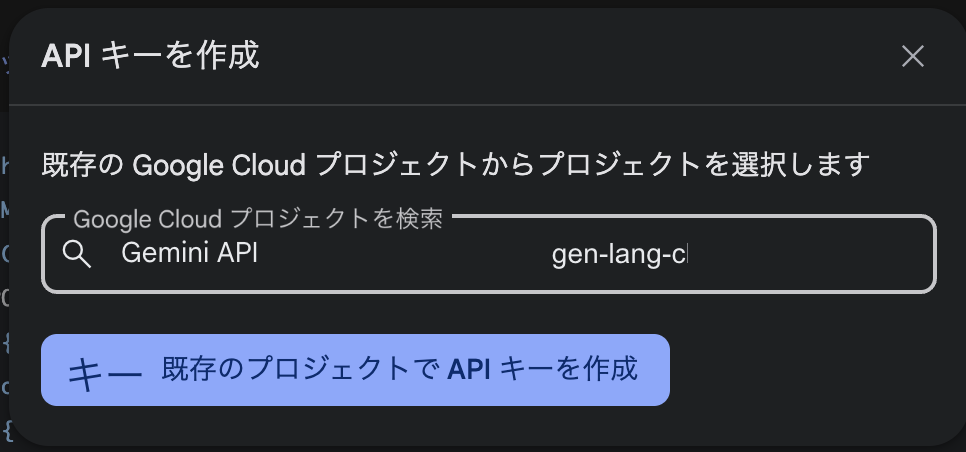
APIキー作成(既存のプロジェクトがある場合)
すでにAPIキーを作成している場合は、プロジェクトを選択して【既存のプロジェクトでAPIキーを作成】をクリックします。
APIキーの発行
APIキーが発行されたら、コピーして忘れないようにメモしておきます。また、このキーは外部に流出しないように注意してください。
Pythonサンプル
ファイル構成
python_samples/
├── images
│ └── cappuccino.webp
└── whats_photo.py
事前準備
Pythonの環境構築は人それぞれですが、今回は、macOSのvenvで説明します。
環境構築(venv)
venvで、Pyhonの環境構築をします。
ターミナル
python3 -m venv .venv
アクティベート
作成した環境にアクティベートします。
ターミナル
source .venv/bin/activate
画像ファイル
images/ フォルダを作成し、画像を用意しておきます。

ライブラリ
Pythonの各種ライブラリを、pip または conda でインストールします。
| ライブラリ | 説明 |
|---|---|
| google-generativeai | Gemini APIライブラリ |
| python-dotenv | 環境設定ファイル「.env」読み込みライブラリ |
| Pillow | 画像ファイル操作ライブラリ |
インストール
各種ライブラリを pip コマンドでインストールします。
ターミナル
pip install -q -U google-generativeai
pip install python-dotenv
pip install Pillow
- Anacondaを利用している場合は condaコマンド
画像認識プログラム
APIキー設定
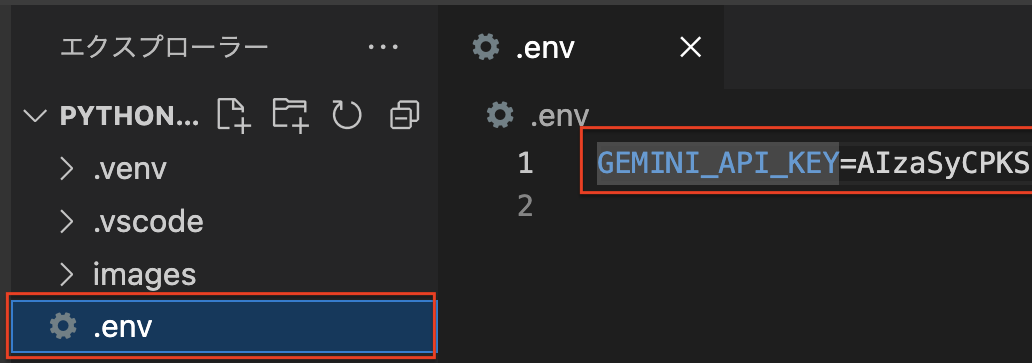
.envファイルを作成し、GEMINI_API_KEYにAPIキーを設定します。
ライブラリインポート
各種ライブラリをインポートします。
whats_photo.py
import google.generativeai as genai
import PIL.Image
import os
from dotenv import load_dotenv
APIキー読み込み
.envの環境変数から API キーを取得します。
whats_photo.py
import google.generativeai as genai
import PIL.Image
import os
from dotenv import load_dotenv
# .env ファイルを読み込む
load_dotenv()
# 環境変数から API キーを取得
API_KEY = os.getenv("GEMINI_API_KEY")
プロンプト作成
配置した画像を読み込み、プロンプトを作成します。
whats_photo.py
import google.generativeai as genai
import PIL.Image
import os
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("GEMINI_API_KEY")
# 画像読み込み
img = PIL.Image.open('images/cappuccino.webp')
# Gemini APIプロンプト
prompt = "この写真はなんですか?"
LLMモデル
LLMモデルとは
LLMのモデルは自然言語の理解や生成を行うモデルのことで、Gemini APIのモデルは以下のものがあります。
モデルの種類(2024/09現在)
| モデル | 入力 | 出力 | 用途 |
|---|---|---|---|
| gemini-2.0-flash | 音声、画像、動画、テキスト | テキスト | 高速で汎用性のさらに高いパフォーマンス |
| gemini-1.5-flash | 音声、画像、動画、テキスト | テキスト | 高速で汎用性の高いパフォーマンス |
| gemini-1.5-pro | 音声、画像、動画、テキスト | テキスト | コード生成やテキスト生成などの複雑な推論タスク |
| gemini-1.0-pro | テキスト | テキスト | 自然言語タスク、マルチターン テキストとコードチャット |
| text-embedding-004 | テキスト | テキスト | テキスト文字列の関連性の測定 |
| aqa | テキスト | テキスト | 質問に対してソースに基づいた回答を提供 |
- 詳しくは Google AI Developer のドキュメントを確認
whats_photo.py
import google.generativeai as genai
import PIL.Image
import os
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("GEMINI_API_KEY")
img = PIL.Image.open('images/cappuccino.webp')
prompt = "この写真はなんですか?"
# Gemini API にAPIキー設定
genai.configure(api_key=API_KEY)
# モデル指定(gemini-1.5-flash)
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
リクエスト&レスポンス
Gemini APIに、プロンプトと画像をリクエストします。レスポンスがあれば、内容をテキスト表示します。
whats_photo.py
import google.generativeai as genai
import PIL.Image
import os
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("GEMINI_API_KEY")
img = PIL.Image.open('images/cappuccino.webp')
prompt = "この写真はなんですか?"
genai.configure(api_key=API_KEY)
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
# Gemini APIリクエスト&レスポンス
response = model.generate_content([prompt, img])
if (response):
print(response.text)
else:
print("Gemini Error")
プログラム実行
ターミナルでプログラムを実行します。
python whats_photo.py
動作確認
Gemini APIからのレスポンスが表示されました。
結果
それは、ソーサーに乗ったカフェラテです。
Node.jsサンプル
ファイル構成
node_samples/
└── chat.js
事前準備
Node.jsの用意
Node.jsをあらかじめインストールしておきます。インストールや基本に関しては「 Node.js超入門」を参考にしてください。
Node初期化
プロジェクトフォルダ内で、npmで初期化します。
ターミナル
npm init -y
ライブラリ
Node.jsの各種ライブラリを、npmでインストールします。
| ライブラリ | 説明 |
|---|---|
| @google/generative-ai | Gemini APIライブラリ |
| dotenv | 環境設定ファイル「.env」読み込みライブラリ |
| Pillow | 画像ファイル操作ライブラリ |
インストール
各種ライブラリを pip コマンドでインストールします。
ターミナル
npm i @google/generative-ai
pip install python-dotenv
pip install Pillow
画像ファイル
images/ フォルダを作成し、画像を用意しておきます。
ライブラリ
Pythonの各種ライブラリを、pip または conda でインストールします。
| ライブラリ | 説明 |
|---|---|
| google-generativeai | Gemini APIライブラリ |
| python-dotenv | 環境設定ファイル .env 読み込みライブラリ |
| Pillow | 画像ファイル操作ライブラリ |
インストール
各種ライブラリを pip コマンドでインストールします。
ターミナル
pip install -q -U google-generativeai
pip install python-dotenv
pip install Pillow
- Anacondaを利用している場合は
condaコマンド
画像認識プログラム
APIキー設定
.env ファイルを作成し、GEMINI_API_KEY にAPIキーを設定します。
ライブラリインポート
各種ライブラリをインポートします。
whats_photo.py
const { GoogleGenerativeAI } = require("@google/generative-ai");
const fs = require("fs");
APIキー読み込み
.env の環境変数から API キーを取得します。
whats_photo.py
const { GoogleGenerativeAI } = require("@google/generative-ai");
const fs = require("fs");
// .env読み込み
require('dotenv').config();
const GEMINI_API_KEY = process.env.GEMINI_API_KEY;
メインプログラム
メインプログラム run() を作成し、メッセージを表示します。
whats_photo.py
const { GoogleGenerativeAI } = require("@google/generative-ai");
const fs = require("fs");
require('dotenv').config();
const GEMINI_API_KEY = process.env.GEMINI_API_KEY;
const genAI = new GoogleGenerativeAI(GEMINI_API_KEY);
async function run() {
const prompt = "What's in this photo?";
console.log(prompt);
}
run();
プロンプト作成
配置した画像とプロンプトを Gemini APIにリクエストします。 レスポンスされると、Geminiの回答が表示されます。
whats_photo.py
const { GoogleGenerativeAI } = require("@google/generative-ai");
const fs = require("fs");
require('dotenv').config();
const GEMINI_API_KEY = process.env.GEMINI_API_KEY;
const genAI = new GoogleGenerativeAI(GEMINI_API_KEY);
async function run() {
const prompt = "What's in this photo?";
console.log(prompt);
const model = genAI.getGenerativeModel({ model: "gemini-1.5-flash" });
const result = await model.generateContent([
prompt,
{
inlineData: {
data: Buffer.from(fs.readFileSync('./images/cappuccino.webp')).toString("base64"),
mimeType: 'image/webp'
}
}]
);
console.log(result.response.text());
}
run();